|
mlpack
blog
|
Deep Learning Modules - Summary
Goals for the summer
I These were the following algorithms I proposed for implementation: RBM, ssRBM(spike slab rbm), GAN(Generative Adversarial Networks), stackedGAN
Executive Summary
I was able to implement RBM, ssRBM and GAN this summer. Though unfortunately none of my code has been merged till now. You can find the PR's that opened below: RBM*, ssRBM, GAN, ResizeLayer Implementation, CrossEntropyWithLogits
- Note
RBMPR was later merged with thessRBMPR.
The ssRBM and rbm are ready to be merged. The GAN PR is also mostly complete. I think only superficial style changes are required.
In addition to implementing these algorithms. I am happy to say that RBM, ssRBM and GAN are very well tested. You can find some of the code here. I would also like to point out that for RBM we are comparable to the sklearn library in terms of speed(1.5x faster) and accuracy(similar). We couldn't benchmark the ssRBM, as none of the libraries actually implement the ssRBM PR. For GAN's we tested out implementation with examples from keras and tensorflow. I am happy to say that in terms of visual reconstruction for the Gaussian distribution generation we were able to get comparable results with tensorflow. We also implemented the test for generation of Mnist images using FFN as the discriminator and generator network. The results are not as good as that of the keras example but we can see the training of Gan and that it converges to some stable results. You can look at the results below.
RBM
The major difficulty with implementing RBM's was deciding on architecture that could easily be extendable to other extensions. Hence, we decided to implement wrapper layer and then implement the actual working of a type of rbm's as policies. This gives us the advantage of modularity.
Here are the results of our implementation on the digits dataset(smaller version Mnist).
The samples are generated from 1000 steps gibbs sampling

This is image is generated from deeplearning.net example

Our accuracy on the digits dataset was around 86% be this can go higher with some more parameter tuning.
Refrence for Implementation: DeepLearning.net, Training RBM
ssRBM
Spike and Slab RBM were hardest to implement mainly because there are no existing implementations of the paper. We had to figure out some formulas ourselves like the free energy function. Some of the details in the paper are a little unclear like the radius parameter for rejecting samples etc. We also had to decide how we wanted to represent parameters such as spike variables, slab variables and lambda bias variables the paper states them to diagonal matrices but we found that most of the papers just have constant value for the diagonal entries so, we decided to represent them as scalar, giving us major speed and memory improvements.
We tested ssRBM on digits data set again we were able to get an accuracy of around ~82% with the digits dataset. One of the reasons accuracy of ssRBM is less than binary RBM is because ssRBM is suited for a dataset that has high correlation within the parts of the images something like the cifar dataset so the correlation can be captured by the slab variables. We tried ssRBM on the cifar data set code but due to the large volume of data set and scarcity of the computation resources, we got around 70% accuracy but the results should be taken with a bit of salt as I saw that increasing of samples size lets to decrease in the accuracy.
We also tried bringing down the running time of the ssRBM considerably and were able to do so. We are still looking at the issue to gain possibly more improvements. We tried the cifar data set for ssRBM testing there were a couple of problems, the paper didn't give a detailed list of parameters that it used either for training the ssRBM nor for the creation of features vectors from the ssRBM for testing. Also, the cifar dataset set is quite huge and the problem was compounded by the fact the paper suggested that we create patches 8*8 from every image, leading to an increased size in the dataset set.
Refrences: Main Paper, Additional Paper1, Additional Paper2
GAN
We implement the Generative Adversarial Networks in a pretty unique way than most of the other implementations in TensorFlow and Pytorch in the following way.
- Using single optimizer for training.
- No need for separate noise data.
- No need to have separate noise and real labels.
- Providing parameters such as Generator Update step defining when to update the generator network.
The main idea of implementing GAN's this way came from Mikhail. The above formulation has the advantage of being easy to use and using fewer resources in terms of space requirements and making a lot more logical sense.
There are at present no techniques for testing GAN's we tested our implementation on the following examples
- 1D Gaussian Test: This test aims to generate data from Gaussian of mean = 4 and var = 0.5 give that the noise function is the uniform distribution.
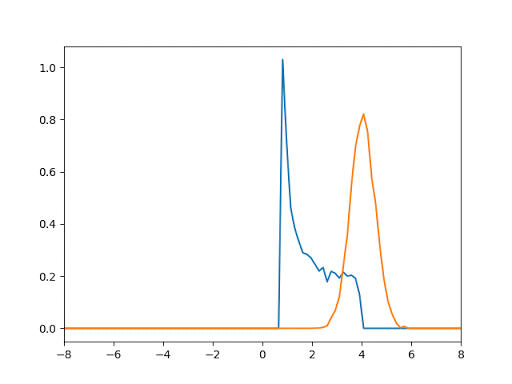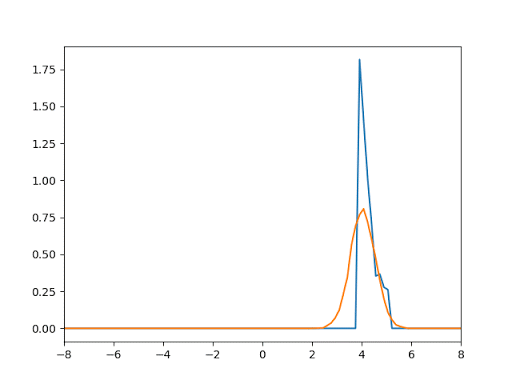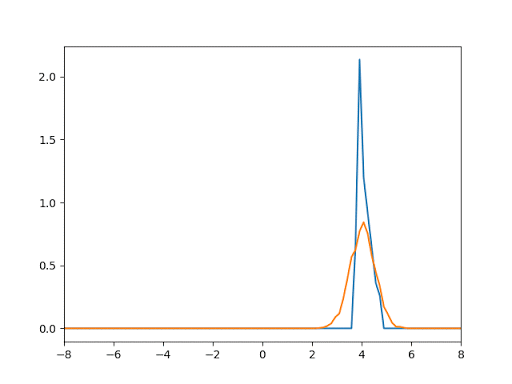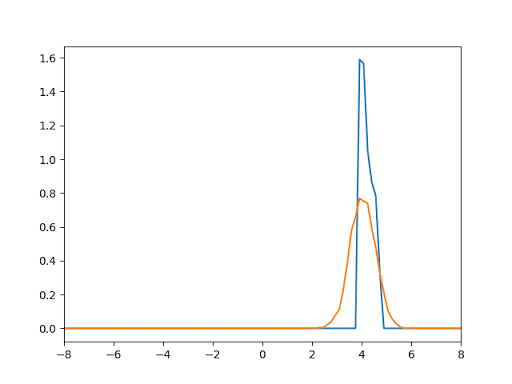
- Generation of Mnist Digits: We tested our
GANfor generation of images using a simple FNN as both the generator and discriminator network. We used only the 7's digits from Mnist data set for achieving the following results.

Here is te final image the network is trained for just 60 epoch's. We can get better results if we find better hyperparameters.

- DcGan(Strip Down Version) We also tested our
GAN'simplementation for generation of digits using CNN's. This basically would give us a simpler version of the famousDCGANimplementation. For completing this test we had to add to the Resize Layer(Bilinear Interpolation of images) and the CrossEntropy with logits layer. Right now we are testing our implementation for this test you can find the code here.
We also added some of the training hacks from Soumith Chintala's workshop on GAN's
- Batch Training for discriminator and generator
- Pre-Training for discriminator
- Optimizing
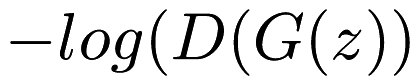 instead of
instead of 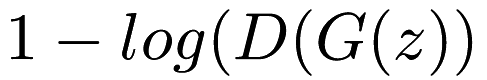
- Training the discriminator more using the Gradient Update step.
Refrences: Gan Paper, Gan Hacks
Highlights
Most of my last 15-20 days were spent in hyper parameter tuning for the various test to work for GAN's and ssRBM. This a highly boring and tedious job. I am really looking forward to the HyperParameter Tuning PR.
One of the major problems faced also was that for testing Deep Learning modules correctly we require huge amounts of data and resources. I found my computing rig in some cases to be very slow for the purpose. Hence, I am looking forward to Bandicoot and testing all this code on a GPU.
I also found the problem of training GAN's particularly the DCGAN example very time consuming there is no efficient way for parameter hyper tuning.
Future Work
- I think ssRBM needs to be tested on data set such as the Cifar but first, we are required to confirm that the existing implementation of
ssRBMdo achieve good results on some parameters so we can replicate the same results. (Preferably this code should be run on GPU since it would lead to faster results and hence faster hyper parameter tuning). - Implementation of Wasserstein
GAN. Lately, a lot of noise in the deep learning community of late has been around how great WGAN are compared toGAN. Hence I think it is reasonable to implement it next. - I think we need support for
DeConvLayers,BatchNormalisationand other image manipulation functions. - I think something similar to hyperopt would be very useful.
- Implementation of stacking module for
RBMandGAN's.
Conclusion
The summer has been quite eventful. I am really happy to say that I have learned a lot about having to persevere through an implementation to make it work. The need for constant improvements of the code base is one of the important lessons I have learned. I also added some serious debugging skills to my skillset. Finally, I want to give a huge thank you to Mikhail Lozhnikov without whom the project would not have been possible. I would also like to thank Marcus for his valuable inputs from time to time and also guiding me with the code base. I really think this experience has made a more patient and much better programmer than I was before. Thanks again to the whole mlpack community :)
Generated by
 1.8.13
1.8.13