|
mlpack
blog
|
Implementing Essential Deep Learning Modules - Week 6
Another wonderful week passed by and we have exciting news to share! Both the Batch Support and DCGAN PRs are now merged, and we have begun our work on Dual Optimizer and Wasserstein GAN, which would be our priority for the coming two weeks.
After all the time spent optimizing and training the network, we have been able to reduce the training time of ~80 hours with singular inputs, to less than 10 hours with a mini-batch of 50 inputs. This is atleast 1.5x faster than the corresponding training time of Tensorflow on CPU! Here are some results that we obtained:
70,000 Images
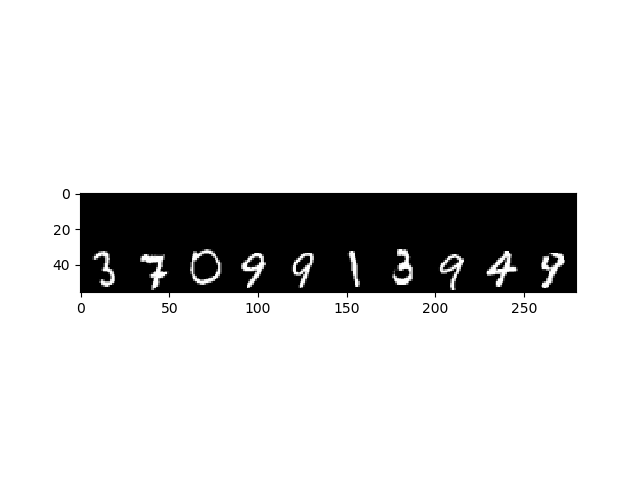
We're currently in the process of deciding the optimal structure for the Dual Optimizer class, and implementing Gradient Penalty and Weight Clipping modules for WGAN. After these issues are sorted, we'd be free of our main goals by Phase II evaluations!
Bidāẏa
Generated by
 1.8.13
1.8.13