|
mlpack
blog
|
LMNN (via Low-Rank optimization) & BoostMetric Implementation - Summary
Google Summer of Code Project Objectives :
Through my proposal, I aimed for implementing LMNN (Large Margin Nearest Neighbors) & BoostMetric distance metric learning techniques.
LMNN Implementation :
Initially, the goal was to have a LMNN implementation based upon Low-Rank SDP optimizer. Though, after some realizations, it eventually got converted into a low-rank linear optimization problem, completely removing the SDP projection step from the picture, meanwhile keeping the base idea of LMNN intact.
This low-rank formulation leads to an initial implementation (#1407 LMNN distance learning) which is generic in term of the optimizer, means most of the optimizer can easily be plugged into the LMNN, allowing LMNN to easily exploit most of there characteristics. For instance, the implementation allows the user to easily select one from AMSGrad, Big Batch SGD, SGD & L-BFGS by simply passing an optimizer flag.
The process just didn't stop there, many more exciting optimizations were still to be employed. The few starting ones include -
- Pruning inactive constraints.
- Employing batches while using SGD based optimizers such as AMSGrad, Big Batch SGD and SGD.
Here are some simulations we got from #1407 with a value of k as 3.
| Dataset | mlpack | shogun | matlab |
|---|---|---|---|
| Runtimes (secs) | Runtimes (secs) | Runtimes (secs) | |
| iris | 0.028843 | 1.340270 | 1.816999 |
| satellite | 6.099969 | 122.910678 | 1161.872116 |
| ecoli | 0.020087 | 5.918733 | 90.625 |
| vehicle | 0.620096 | 18.766937 | 55.068948 |
| balance | 0.071944 | 10.840742 | 3.332948 |
| letter | 19.975593 | 6416.926464 | - |
| Dataset | mlpack | shogun | matlab |
|---|---|---|---|
| Accuracy (%) | Accuracy (%) | Accuracy (%) | |
| iris | 97.3333 | 97.33333 | 96.0 |
| satellite | 93.10023 | 94.77855 | 93.58974 |
| ecoli | 91.071428 | 92.410714 | 90.625 |
| vehicle | 81.6785 | 80.023640 | 65.24822 |
| balance | 90.72 | 81.28 | 77.60 |
| letter | 97.0 | 97.095 | - |
Illustration of learning curve over seed dataset :
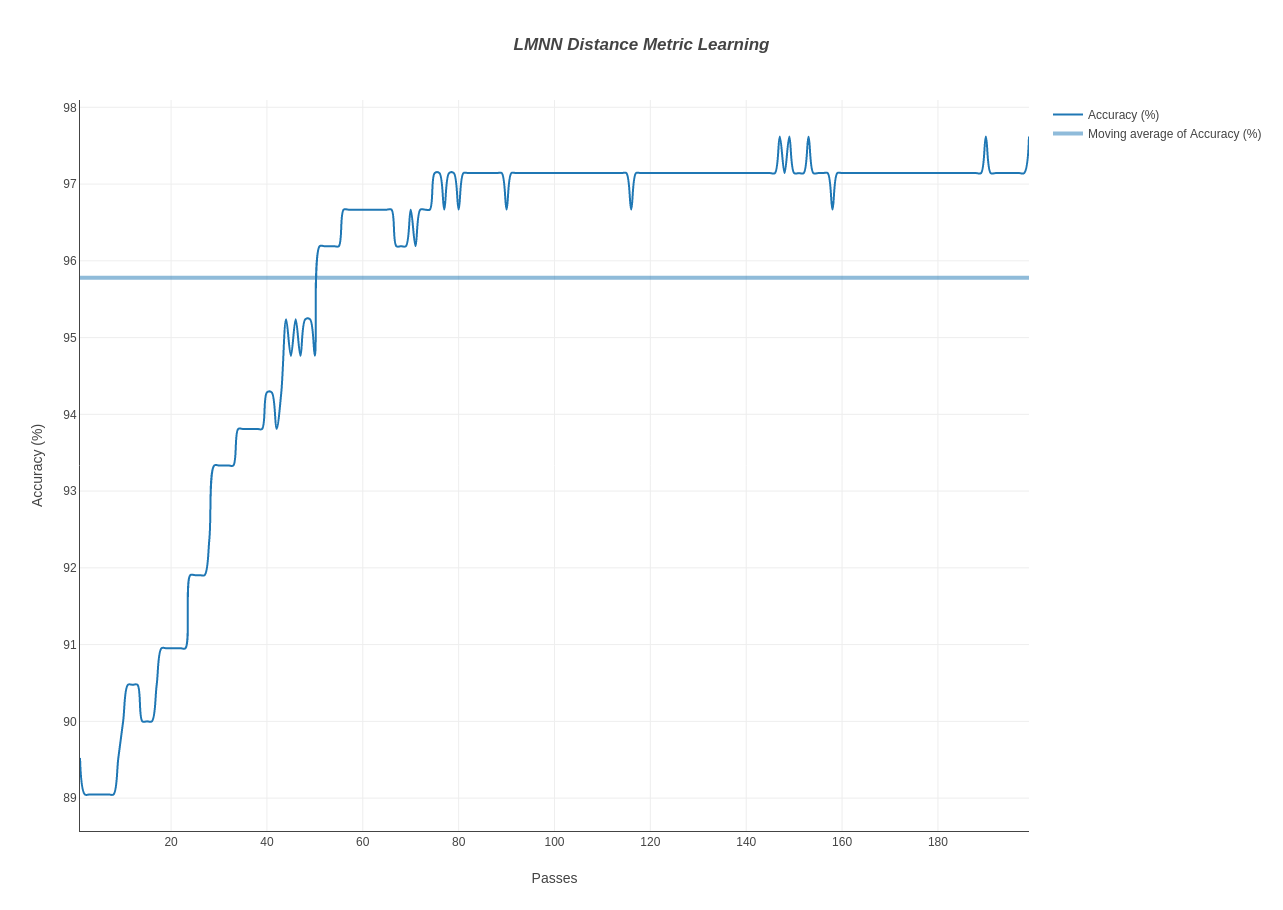
After finishing up #1407, the next step was to perform a number of other substantial optimizations and this lead to opening of several issues -
- #1445 LMNN: optimization of kNN computation by tree caching
- #1446 LMNN: optimization of kNN computation by bound relaxation
- #1447 LMNN: low-rank matrix optimization
- #1448 LMNN: optimization by avoiding impostor recalculation using bounds
- #1449 LMNN: optimization by bounding slack term
Out of those #1447, #1448 and #1449 were successfully handeled together with verifying correctness and speedups from each one of them. #1445 & #1446 are still in progress and hopefully will be completed in very near future.
The simulation (performed with same parameters as of above benchmarks) below depicts the current LMNN (after performing optimizations) performance:
| Dataset | ||
|---|---|---|
| Runtimes (secs) | Accuracy (%) | |
| iris | 0.014874 | 97.3333 |
| satellite | 2.802369 | 94.0793 |
| ecoli | 0.016140 | 93.75 |
| vehicle | 0.600228 | 78.8416 |
| balance | 0.074875 | 93.44 |
| letter | 31.89887 | 97.0 |
Here's an illustration of result of lmnn learning over a dummy dataset -
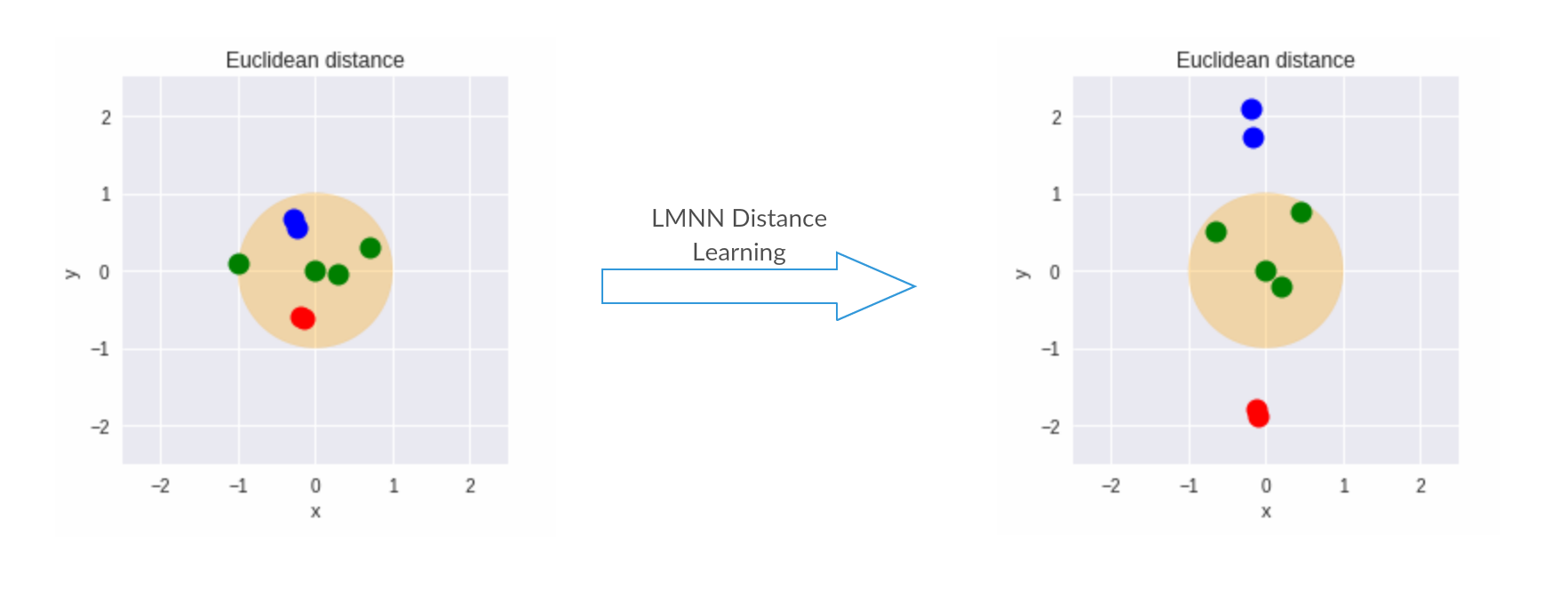
Finally, Here's a record of all PR's relevant to LMNN implementation -
- Merged :
- Open:
- Closed:
BoostMetric Implementation :
A major portion of the project time went into developing a novel implementation of LMNN, which led to a shortage of time for handling BoostMetric. Even though facing limited time constraint we were able to successfully implement it. Here's the BoostMetric PR #1487 Implementation of BoostMetric Distance Learning which is currently in the open state. Hopefully, it will be merged very soon as well, once we get sufficient results to convince ourselves. We even ran a number of simulations against our LMNN implementation to get an idea of what more can be improvised.
Highlights
- The very initial task of framing the SDP problem into a low-rank linear optimization problem and then verifying its correctness, itself consumed quite an amount of time & mental resources.
- Efficiently calculating the target neighbors & impostors for each data point was a challenge in itself. For this, we are already exploiting a major portion of the code & physical structure of nearest neighbors & binary space trees that are already there in mlpack. Perhaps we will see even further speedups, ones the work related to #1445 & #1446 completes.
- Deriving & implementing bounds, furthermore seeing speedups coming through at the same time, was the phase that was the most exciting one. We derived numerous bounds for different LMNN terms (honestly most of them were the adaptation of initial bounds derived by my mentor, Ryan) and the best part is we got to see some good amount of speedups from each one of those. Though sometimes results were highly dataset dependent.
- Truly speaking, performing simulations was one of the most tedious but can't deny, it was one of the most valuable as well. Sometimes it even used to take days to see the results. But I was fortunate enough to have a caring mentor and organization, who aided me at every point and even provided me the access to a good build system, which made this work a lot easier.
- Visit all previous GSoC blogs.
Conclusion
Ah, this was one of the best experience I ever had. I didn't thought that these 3 months will pass this quickly. Each and every day was full of new encounters. I couldn't have expected more. I am thankful to Ryan, Marcus & whole of the awesome mlpack organization for this wonderful period of time. Thanks, Ryan for always being there and helping me out at each and every step. I appreciate all the help you provided and all the patience you kept with me. Without your thoughtful & clever ideas, I don't think the project could have been in the state, it is now. Also, a big thanks to Marcus for helping out every time I asked. I really appreciate all you did for me when I was stuck with benchmarking scripts. Finally, I am grateful to Google for providing me a once in a lifetime experience, eventually making me more comfortable with open source. GSoC is definitely a novel program helping thousands of students worldwide. (◕‿◕)
Generated by
 1.8.13
1.8.13